ברוכים הבאים לסדרת פרקים על שפת השאילתות - SQL ומסדי נתונים.
מה כדאי לי לדעת לפני הקריאה?
- מחשבים באופן בסיסי
- קבצים
- שפת תכנות ברמה בינונית
מה נלמד בפרק הזה?
- מה זה מסדי נתונים
- אילו מסדי נתונים קיימים והסוגים שלהם
- מה זה SQL?
- תחביר שאילתא בסיסית
- כתיבת שאילתות בסיסיות
הפרק הזה יתמקד בבסיס ובכניסה לעולם מסדי הנתונים.
מה זה מסד נתונים?
מסדי נתונים הם רכיבי תוכנה - תוכנות כמו שאנחנו מכירים, אשר נותנים לנו יכולות אחסון ואחזור על מידע.
המידע הקלאסי הוא מידע מסוג טבאלי או בשפה המקצועית - relational database.
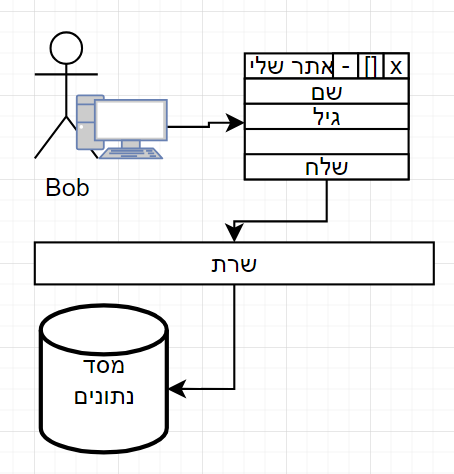
הדוגמא הקלאסית היא שאתם נכנסים לאתר ונרשמים למערכת.
אתם מגישים להם את השם שלכם והגיל שלכם והאתר מעבד את המידע.
מה הגישה שבדרך כלל מתבצעת?
האתר שולח את המידע לשרת כלשהו.
השרת הזה אוגר את המידע במשהו שנקרא - מסד נתונים.
מה מסד הנתונים הזה נותן לנו? למה לא לשמור את המידע לקובץ וזהו?
למה לא לשמור את המידע לקובץ?
קבצים ומסדי נתונים
נניח ואנחנו רוצים פתרון פשטני ונשמור את האדם לקובץ.
כעת נצטרך להחליט:
- לאיזה קובץ לשמור
- איך לשמור את המידע
- איך לאחזר את המידע
לאחזר זה אומר לשלוף את המידע חזרה וחיפוש עליו.
פתרון א’ - האופן הפשוט
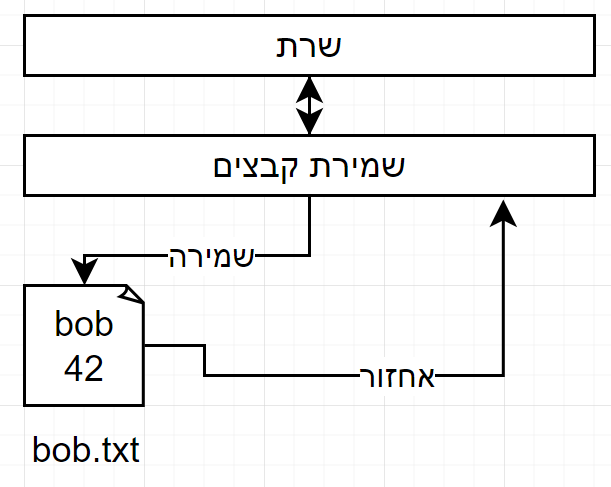
הפתרון הפשוט הוא לשמור את זה לפי שם האדם.
יש לנו את השרת,
נכתוב שכבת קוד המטפלת בשמירה וטעינה של קבצים.
אם רוצים לאחזר את המידע לפי שם האדם זה מאוד קל כי זה שם הקובץ, אתם ניגשנים לפי השם ומוציאים את המידע.
הפתרון הראשון מציע פתרון לשני בעיות הכי פשוטות במסדי נתונים:
- שמירה של מידע.
- אחזור של מידע.
אחזור של מידע הוא תהליך סטנדרטי של הבאת המידע ע”פ קריטריונים מסוימים.
כמו שתיארנו השלב הראשון הוא ללא כל קריטריון.
השלב השני הוא ע”פ קריטריון בסיס - פיסת מידע המאפשרת לנו לאחזר, כמו שם של אדם.
מה ייקרה אם לשני אנשים יש את אותו השם?
ניתן ליצור מזהה ייחודי ולשלוף על פיו, כמו תעודת זהות, אין שני אנשים עם אותו מספר תעודת זהות.
בשלב השלישי אנחנו עוברים מקריטריון בודד לכמה קריטריונים.
אנחנו לא שולפים את המידע על מנת לשלוף עצם בודד, אלה רוצים להתייחס למידע ככלל.
במקום אדם בודד - כל האנשים.
ועכשיו נשאל שאלה -
אני רוצה לדעת כמה אנשים יש בטווחי הגילאים 20-40.
איך אני עושה את זה בפתרון הפשוט?
- קוראים קובץ קובץ
- שומרים את הנתונים במערך
- ניתן גם לשמור רק את המידע הרלוונטי, ישר לבדוק אותו.
פתרון ב’ - קריאה עם תנאים
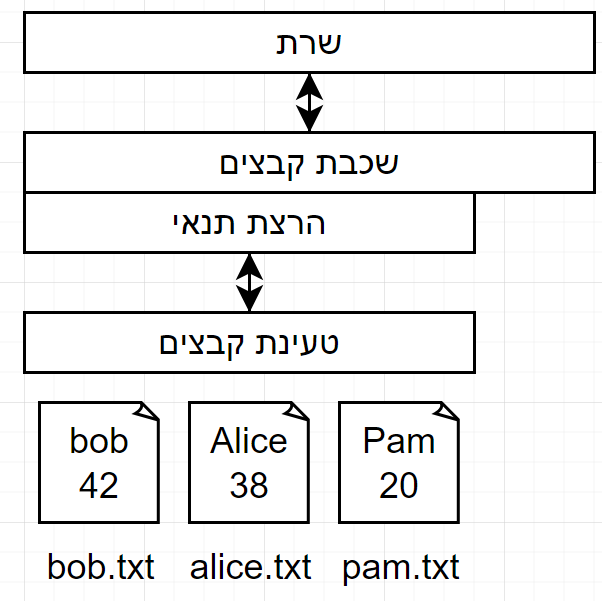
כעת נכתוב קוד כזה בפייתון:
1 | import os |
תנאים הם דבר הכרחי לאחזור מידע, בדרך כלל יעניין אותנו סוגים שונים של תשובות ולא רק תשובה בודדה.
אם נבדוק את אורך הרשימה נדע כמה אנשים הם בני 20 עד 40.
פתרון ג’ - הוספת מידע
האתר מרחיב את פעילותו והדרישה כעת להוסיף גם מקומות.
אז באותה הדרך נשמור קבצים לאנשים וקבצים למקומות:
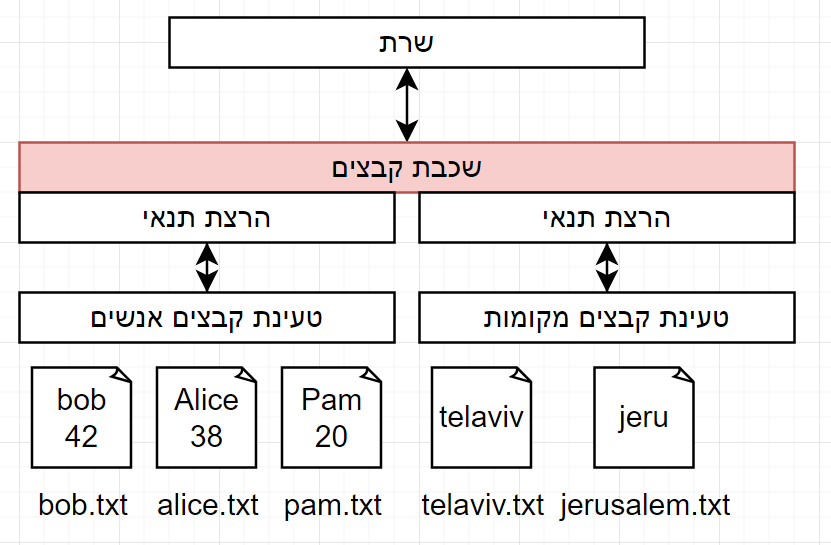
יש לנו סכימה לאיך לשמור את הקבצים ואיך לאחזר אותם.
מה קורה אם צריך להוסיף מידע חדש?
פשוט מוסיפים סוגי קבצים חדשים למערכת.
סיכום הפתרונות
שימו לב לאיך הרחבנו את שכבת הקבצים, במקום לשמור הכל בזיכרון או בקובץ אחד,
בנינו מערכת המסוגלת לשמור ולשלוף קבצים ע”פ פרמטרים ולהריץ עליהם תנאים!
במקום מערכת קבצים למערכות כאלו קוראים - מסדי נתונים.
וזה מה שמסד נתונים מעניק לנו, את היכולת לשמור מידע בצורה מסוימת בפורמט מסוים ולאחזר עליו.
סוגי מסדי נתונים
בשנים האחרונות חל שינוי גדול בהתנהגות ומהות מסד הנתונים.
בדוגמא שראינו שמרנו מידע מאוד בסיסי ופשוט ולא הרחבנו מעבר את היכולות של מסד הנתונים.
בנוסף כתבנו יכולת לאחזר את המידע - מסדי נתונים מעניקים יכולת לאיך לשלוף את המידע.
ואפילו יכולות נוספות כגון שפה לשליפה, מנגנון פרוצדורות שמור, אינדקוס המידע וכדו’…
ככל שהתרחבו התעשיות ועוד ועוד דומיינים דרשו פתרונות תוכנה נכנסו מגוון פתרונות למסדני נתונים.
נתחיל ונחזור על המסד נתונים הפשטני והמוכר - Relational Database Managment System (RDBMS).
RDBMS - Relational Database Managment System
המידע שנשמר שם מסוג טבלה עם שורות ועמודות.
שורה זה מופע חדש של המידע.
וכל עמודה שומרת תכונה על המידע שנשמר.
למשל טבלה של אנשים עם המזהה שלהם, השם והגיל:

כל סוג מידע חדש אתם בעצם פותחים טבלה חדשה - תדמיינו אקסל על סטרואידים - משהו כזה.
SQL - Structured Query Language
מסדי נתונים מסוג רלציוני מעניקים לנו שפה ייחדות לשליפות.
אפשר לקרוא לזה “שפת שליפות מובנית” או באנגלית - SQL.
יש כאלו המבטאים כל אות בנפרד - S.Q.L,
או קוראים את זה כ-Seqeuel.
השפה כתובה בצורה די פשטנית ונותנת לנו יכולות שליפה, ביצוע תנאים, אגרגציה ואף ניהול ותמיכה במסד נתונים.
כגון שינוי הקצאות זיכרון, בדיקת יוזרים וכדו’.
למשל אם נרצה לשלוף את כל המידע על טבלת אנשים:
1 | SELECT * FROM PEOPLE |
“לבחור את כל העמודות מטבלת האנשים”.
זוהי השפה שבה אנו נעסוק, ונגוון עם כל מיני מסדי נתונים התומכים בשפה הזו.RDBMS הוא לא מוצר ספציפי אלה סוג של מסד נותנים, עליו נלמד.
דוגמאות ל RDBMS
MySQLMicrosoft SQL ServerOracleDBPostgreSQLSQLiteMariaDB
No SQL Databases
זהו גם מסד נתונים אך הוא מאגד נתונים לא בצורת טבלאות עם שורות ועמודות, אלה קובע סוג אחר של מידע אשר נשמר שם.
גם כך יכולות האחזור שלו שונות ובדרך כלל כל מסד נתונים מתאים לדומיין אחר.
אחד מהמסדים הבולטים בתחום הוא MongoDB אשר שומר את הפריטים בפורמט Json.
ומאפשר לאחזר ע”פ שפת שאילתות מבוססת json עם שליפה עם JPath.
עוד מסד נתונים המאפשר גם שליפות בעזרת שפת SQL:
Couchbase Server

Key-Value Data stores
כאשר לא מעוניינים לשמור מסמכים שלמים אלה רק מפתח עם ערך מסוים, סוגי המסדי נתונים האלו מועילים לנו.
לעיתים אנחנו נשתמש בהם כיכולת לשמור זיכרון מטמון (Cache) במקום אשכרה כמסד נתונים לכל דבר.
אחד המוצרים הפופולריים בתחום הזה נקרא Redis.

Graph Databases
צורת מידע לשמירת גראפים, כאשר גרף מוגדר כאוסף נקודות או Nodeים עם קישוריות בין שני נקודות.
כל קישור מהווה “קשר” מסוים ולו מתווסף פרמטר הנקרא משקולת - או כמה חזק הקשר בין השניים.
לדוגמא אתם יכולים לתאר את המערכות היחסים שלכם עם אנשים שונים, לחלקם יהיה קשר חזק יותר ולחלקם קשר חלש יותר.
עם מכרים מהעבודה או מהאוניברסיטה יהיה לכם קשר יחסית חלש,
עם המשפחה שלכם ככל הנראה הקשר יהיה חזק יותר.
מסד נתונים פופולרי הוא ה-GraphDB.
Time series Database (TSDB)
מסד נתונים העובד על מידע בנקודות זמן שונות.
איזה סוג של מידע יכול להתאים פה?
- מידע על הבורסה.
- מידע על מזג אוויר.
- צריכת חשמל
בעצם כל מקום שבו אינטרוול זמן הוא חשוב, ניתן להשתמש במסד נתונים היעיל בזמנים.
המסד הנתונים הפופולרי בתחום הוא InfluxDB.
Search Engines
מסדי נתונים אלו מאופיינים ביכולות האינדוקס הטובות שלהם.
אינדוקס זהו תהליך של שמירת המידע כדי לשלוף אותו מהר יותר.
אנחנו מגדירים לפיסות מידע שונות מה אנחנו רוצים לאנדקס ועל פי הבקשה הזו נוכל לאנדקס את זה בצורה יעילה יותר.
לטובת קריאה מהירה יותר, או כתיבה מהירה יותר.
למשל אם אקח את דוגמת שמירת הקבצים שדיברנו עליה בפוסט הזה, הקבצים נשמרים לפי השם.
1 | alice.txt |
נניח ויש שני אנשים עם אותו שם, אז נשים מספרים עם השם כדי לדעת שאלו אנשים שונים:
1 | alice.txt |
נניח אני רוצה לקרוא רק מי שקוראים לו bob.
אני יכול לאנדקס את השמות לתיקיות על פי השם:
1 | \a |
עכשיו אם ארצה לקחת את כל הבובים זה יהיה מאוד קל כי פשוט אגד לתיקיית \b\o\b\ ואקח את כל הקבצים משם.
אחד ההמצאות הישראליות הגדולות בשנים האחרונות הוא מנוע ה-ElasticSearch - https://www.elastic.co/elasticsearch
רוב המנועים האלו יודעים לאחזר ולאנדקס כמויות של טקסט.
למשל עבור אנדוקס תגובות בפייסבוק, ככה שפייסבוק יכולים לחפש על פי תוכן התגובות.
Big Data
חלק מהמסדים שהזכרתי עובדים יפה עבור כמות גדולה של מידע.
אך יש כמות מידע שנהיית כל כך גדולה שזה כבר לא מתאים למסדי נתונים.
במיוחד אם אנחנו רוצים לאחזר ולחפש על פי תוכן לא סטנדרטי כמו סרטונים, טקסט, מידע על פי זמן וכדו’..
אחד הפיתוחים הפופולריים בתחום הוא ה-Hadoop.
בשיטת ה-Map-Reduce הם יכולים לאחזר על כמויות עצומות של מידע בלתי תלוי.
הם אפילו פיתחו מערכת קבצים משל עצמם הנקראת HDFS.
שלום מסד נתונים ראשון
אנחנו נדגים את מסדי הנתונים בעזרת פייתון ו-SQLLite.
SqLite זהו סוג מסד נתונים מאוד פשוט הנותן לשמור את הכל לתוך קובץ אחד.
שכבת ה-sqlite היא שמנהלת עבורנו את הכל.
נכתוב סקריפט פשוט המתחבר לקובץ ויוצר טבלה עבור שמירת אנשים.
שימו לב שאנחנו משתמשים ב-import sqlite3 המגיעה כבר עם פייתון.
1 | import sqlite3 |
שפת SQL - הבסיס
השפה מגדירה תחביר המתאר פקודות למסד נתונים.
כל בקשה כזו נקראת שאילתא.
רוב השאילתות שלנו ייראו כך:
COMMAND <info> SUB-COMMAND <info>
כל פקודה תקבל פרמטרים מסוימים או תתייחס לטבלה מסוימת.
למשל:
SELECT * FROM peopleSELECT - לבחור מהטבלה* - אילו עמודות, כוכבית אומר תיקח הכל אבל היינו יכולים לכתוב אחרת.FROM - מאיזו טבלהperson - טבלת אנשים
ניתן היה לשכתב את זה גם כך:SELECT id,name,age FROM people.
השאילתות נותנות לנו יכולות אחזור אך תזכרו שאנחנו צריכים לבצע דברים אחרים:
- פעולות על טבלאות
- הוספה ומחיקה של עמודות
- הרצת שאילתות מורכבות יותר
כמה נקודות:
- האם עלי לכתוב פקודות באותיות גדולות?
בעקרון לא, אבל זה עוזר להבדלה בין מילות מפתח לשמות טבלאות או עמודות. - האם אני צריך נקודה פסיק בסוף כל שורה?
בעקרון לא, יש מסדי נתונים שיכולים לעבוד גם בלי.
CREATE TABLE
1 | CREATE TABLE people( |
CREATE TABLE - הפקודה ליצירת טבלה.people - שם הטבלה שאותה ניצור.
לאחר מכן בסוגריים מעוגלות אנחנו מגדירים 3 עמודות בטבלה הזו.id INTEGER PRIMARY KEY
החלק הראשון הוא שם העמודה, במקרה הזה -id.
החלק השני מגדיר את סוג המשתנה - זה אומר משתנה מספרי שיכול להיות שלילי או אפס גם.
החלק השלישי נכון רק לשורה הראשונה וזה שהעמודה הזו מגדירה משהו שנקרא Primary Key.
שזהו המזהה העיקרי בטבלה הזו ואסור שיהיה לנו 2 שורות עם אותו המזהה.
אילו עוד שני פרמטרים אנחנו מוסיפים?
INSERT INTO
יצרנו טבלה, אבל היא ריקה.
אז צריך להוסיף רשומות!
1 | INSERT INTO people VALUES |
באותו התחביר אנחנו מגדירים את הפקודה INSERT INTO.
שזה להוסיף לתוך טבלה מסוימת, במקרה שלנו זה people.
אחרי VALUES אנחנו מגדירים את המידע להוסיף.
כל שורה היא בעצם שורה בטבלה כך שהשאילתא הזו מכניסה לטבלה 2 רשומות.
בחור בשם בוב בן 42 עם המזהה 1.
בחורה בשם אליס בת 38 עם המזהה 2
מה ייקרה אם ננסה להכניס את אליס פעמיים?
1 | INSERT INTO people VALUES |
תשובה:
1 | UNIQUE constraint failed: people.id |
המסד מזהה שניסינו להכניס את אותו המזהה בשורה חדשה.
SELECT - הרצה בפייתון
כדי לקחת את הכל נוכל להריץ:
1 | res = cur.execute('SELECT * FROM people') |
שימו לב כמה קל לרוץ על הרשומות בפייתון נטו בעזרת ה-for.
בפוסט הראשון למדנו על מה זה מסד נתונים, מגווני התוכן שנוכל לשמור במסדים והתנסנו במסד הנתונים הראשון שלנו מסוג SqLite.
בפרק הבא נלמד על פילטורים, עדכונים ומחיקות!






